
阿里云推出单机即可训练百亿参数的中文稀疏GPT大模型,登顶 ZeroCLUE零样本学习榜单
2023-09-07 10:36:31来源:看点时报
作者:同润、临在
日前,中文语言理解权威评测基准CLUE公布了零样本学习ZeroCLUE的最新结果,阿里云位于该榜单榜首。此次刷榜的模型是阿里云机器学习PAI团队推出的160亿参数的稀疏模型 GPT-MoE,这也是业界首个中文稀疏GPT大模型在该榜单登顶。
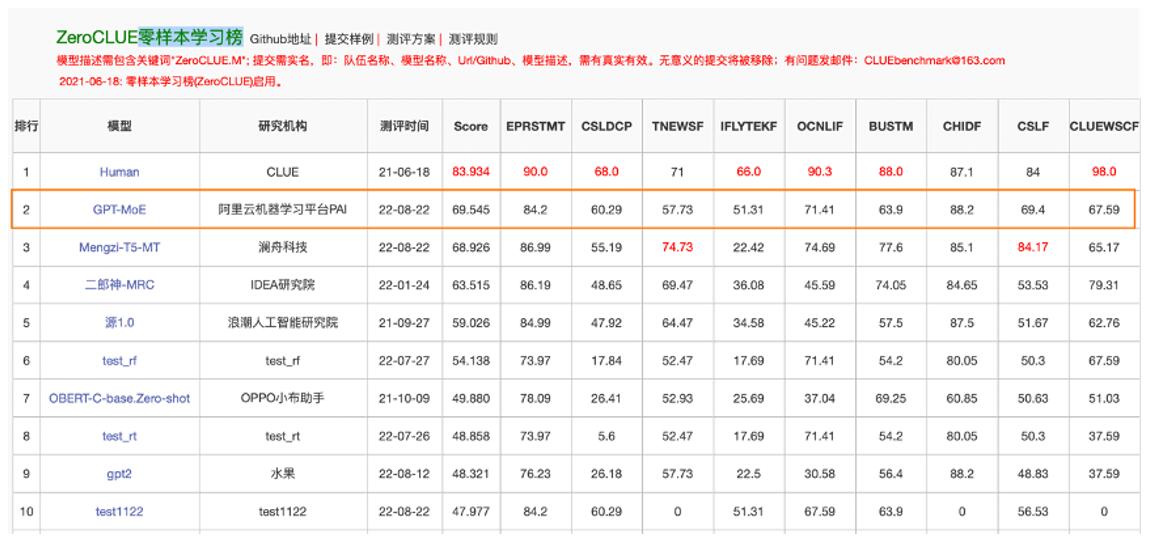
在继去年的Transformer Encoder大模型取得中文小样本学习、英文预训练模型知识量度量冠军后,今年阿里云将大模型技术能力又向前推进了一步。基于MoE稀疏结构,仅用一台A100就把160亿参数量级的多任务通用GPT模型训练成熟。这是通往低成本且高性能多任务通用自然语言理解的重要里程碑。
中文GPT大模型落地主要面临来自两方面的挑战:一方面是中文语言建模的困难,中文可以利用复杂多变的自由组合表达多重含义,这使得中文语言模型比英文在表达效率上难度加倍;另一方面随着模型参数量的不断增加,需要投入的硬件成本越来越高,训练成熟时间越来越长。
以OpenAI推出的1750亿的GPT-3为例,在1024张A100GPU上预估需要34天;因此,能否消耗更少的计算资源以高性价比的方式完成训练和推理是大模型落地亟待解决的难题。
GPT-MoE 模型采用稀疏模型的结构设计,有效缓解了上面提到的两个困难。在刷榜的过程中,从工程到算法沉淀出4点自研核心技术,有强化型稀疏均衡器,领域话术再适应驱动的中文提示语零样本学习,中文复杂任务定向优化,以及阿里云自主研发的transformer训练加速工具Rapidformer,实现了单机A100即可训练160亿参数大模型。
目前,GPT-MoE 模型已在阿里云机器学习PAI EasyNLP项目中开源,和开发者共享中文百亿稀疏GPT大模型技术。
开源项目地址:https://github.com/alibaba/EasyNLP/tree/master/examples/rapidformer
关键词:
责任编辑:hnmd003
精彩推送
- 阿里云推出单机即可训练百亿参数的中文稀疏GPT大模型,登顶 ZeroCLUE零样本学习榜单
- 抢抓节点营销机会窗,TikTok for Businesss助力商家解锁Mega Sales无限商机
- 首个“亿级”美白IP收官,「了不起的美白新科技」引领科学美白新风
- 方里换季粉霜来袭,让底妆焕发新活力
- 开放合作 共向未来 2023石景山国际开放合作论坛开启
- 易海创腾联手Yandex启“杭”东欧,共同掘金俄语市场!
- 今日上市:金帝股份、视声智能
- 工信部党组《求是》杂志撰文:推动数字技术创新和产业发展
- 【机会挖掘】地方鼓励扩大新能源汽车消费 关注产业链机会
- 古代人怎么治癌症:历经传承的帝王养生神器
- “医院买西服”别成糊涂账
- 健身器材换新颜 “快乐健身”更舒心
- 36岁女人越来越胖怎么办_越来越胖怎么办
- 房地产板块高开 我爱我家领涨
- 济宁医学院附属医院肛肠外科(本部)成功抢救两例重度大面积坏死性筋膜炎患者
- 多地官宣“认房不用认贷” 有银行称相关执行细则将很快出台
- ASML称已向荷兰政府申请许可证获批 在今年内仍可向中国出口部分高端浸润式光刻系统
- 9月1日央行公开市场开展1010亿元7天期逆回购操作
- 购房首付比下限、存量首套房贷利率调整落地
- 震裕科技08月31日被深股通减持5.35万股
- 工行农行交行招行等今迎新一轮存款利率下调,最高降幅达25个基点
- 中国银行下调人民币定期存款利率
- 房贷新政八大要点:首付比例怎么调 存量房贷利率能降多少 怎么申请
- 靠周杰伦“数智人”,这家公司上半年增收870万
- 35岁麦基确定签约国王!名记称有点意外:以为他会重回湖人或勇士
- 遥感三十九号卫星成功发射
- 两部门发文引导房贷首付比例和利率下行:做了哪些调整 对楼市有何影响?
- 中国制造全球最大级别环保集装箱船从盐田港首航 1800辆国产新能源车登船出口荷兰
- 男人打呼噜的解决办法有哪些?
- 长二丁一箭三星发射成功
- 不合格儿童学生用品曝光
- 2023年服贸会探营:首钢园区
- 两部门调整优化住房信贷政策
- 银行业保险业“万企千亿”提振信心 今年计划新增对接授信金额超千亿元 力争活动期间每年首贷户新增2万户
- 2023姚基金慈善赛本月17日澳门开打 郭艾伦、弗雷戴特等将参赛
- 工农建交等六银行:推进存量首套房贷利率调整 机构:100万房贷月供可降840元
- 文创之力何以助“燃”文博热
- 利率真要降了!买房人不眠:开始焦虑排不上队 “恨不得明天就是9月25号”
- 南美最大规模太阳能展在巴西圣保罗闭幕
- Xiaomi路由器AX3000T悄然预售 189元秒杀竞品
- 缓解普职分流焦虑,让所有孩子都能“上好学”
- 走读长沙历史
- 9月买手机,这4款旗舰机型值得选,配置全面性能强,保证错不了
- 百强房企前8个月卖了约4.4万亿 保利、万科、中海居前三 碧桂园降至第6名
- 两部门发布房贷新政 降首付比例、房贷利率和存量首套房贷利率窗口已开
- 信息量巨大!房贷政策重要调整 专家最新解读!
- 暑期国内旅游人数达18.39亿人次 亲子游成主流
- 降低存量首套房贷利率 建行农行连夜响应:尽快调整 线上线下便捷服务
- 江油教师招聘 江油教师招聘网
- 2023年暑期档总票房达206.11亿 创中国影史新纪录
- 《2023年中民宿行业洞察报告》:小众目的地旅游消费崛起
- 惠州9月1日起实行“认房不认贷”
- 奇洛教授 奇洛
- 邮储银行(601658)2023年中报点评:特色化引领 增长极赋能
- 中国银行风险总监刘坚东:落实好未来对于存量、增量房贷的政策要求
- 挪威政府决定在今年年底前关闭该国驻马里大使馆
- 原材料跌价增厚下游盈利,光伏组件“五虎”上半年净利暴增
- 上海市嘉定区举办专利对接活动 助力专利成果高效转化
- 丝绸之路沿线民宿创业热情高 上半年哈密民宿房源增速达609%
- 常山江航运开发工程(一期)全线开工建设
- 规范使用地图:2023年版标准地图正式发布
- 中汇人寿明确经营思路 在健康服务平台建设上迈出重要一步
- 万峰受贿案一审开庭
- 降息潮下保险崛起?有人花近10万赶“末班车” 分红型产品成新宠
- 烟雨江湖风铃花环支线任务怎么做 风铃花环支线任务攻略
- 贝壳找房:二季度净利润13亿元,总交易额7806亿元
- 国家医保局:坚持“一品一策” 完善采购规则 高质量开展第四批国家组织高值医用耗材集采
- 上海公布第三批拟出让宅地清单:17宗地总面积约108公顷
- 国航与罗尔斯-罗伊斯合资公司落户北京 预计2026年投入运营
- 广药集团成立本草啤酒公司 瞄准中药加精酿啤酒市场
- “苏拉”挟风雨将至 福建部分地区延迟开学
- 2023下半年陕西省事业单位统一招聘公告发布9月5日开始报名9月23日笔试
- 社旗唐庄乡:开展汛期河道隐患整治工作
- 红桥市场探索绿色商场建设
- 中国人民银行行长、国家外汇管理局局长潘功胜会见彭博公司创始人布隆伯格
- 教育部:2018-2022年国家财政性教育经费累计投入21.4万亿元
- 加强企业信息安全管理 深度数科通过“三级等保认证”认证
- 重庆与21家金融机构签约共建西部金融中心
- 香港天文台:根据“苏拉”风力 香港有机会发出十号风球
- 湖南发布丨湖南上半年接待旅游总人数2.92亿人次,收入4372.46亿元
- 南向资金今日净买入28.31亿港元
- 快快评丨“牛郎织女雕塑”再曝威胁信事件,被搅的浑水到底有多深?
- 武汉官宣“认房不认贷” 9月1日起施行
- New Balance起诉Golden Goose 运动品牌专利纠纷频繁上演
- 实地探访科陆“最佳营收”储能电站?美的能源“羽翼渐丰”
- 我国成功发射遥感三十九号卫星
- 俄媒:俄再次向白俄罗斯交付可携带核弹头“伊斯坎德尔-M”导弹系统
- 今年来江西已办理生态环境损害赔偿案件773件
- 甘肃建“环境应急专家库”提升黄河流域环境应急管理能力
- 外交部:第三届“一带一路”国际合作高峰论坛将于10月在北京举办
- 699元就能双飞出国游? 东南亚旅行团虚位等客
- 尼尔森IQ:中国快消市场迈入复苏轨道 酒水饮料增长提速
- 森保一谈南野拓实等落选:不只近期状态,此前的表现也要考虑进去
- FoFo真的很努力,但没有办法!老岳透露EDG新赛季阵容细节
- “沿着河湖看新疆”主题采访团走进库尔勒市:香梨种植何以实现提质增效?
- 造车新势力资本市场新动向:阿维塔、哪吒获融资,极氪即将赴美IPO
- 5G商业发展分析——持续演进跨入5G-Advanced新阶段
- “渣渣辉”背后的中旭未来通过上市聆讯 毛利率下降后急需证明硬实力
- 8月31日 14:19分 耐普矿机(300818)股价快速拉升
- 中国两部门指导建行开展试点工作破解知识产权“评估难”



